2025 AIChE Annual Meeting
(526b) Optimization of Reaction Pathways in a Lumped Kinetic Model for Fluid Catalytic Cracking Using Reinforcement Learning
Authors
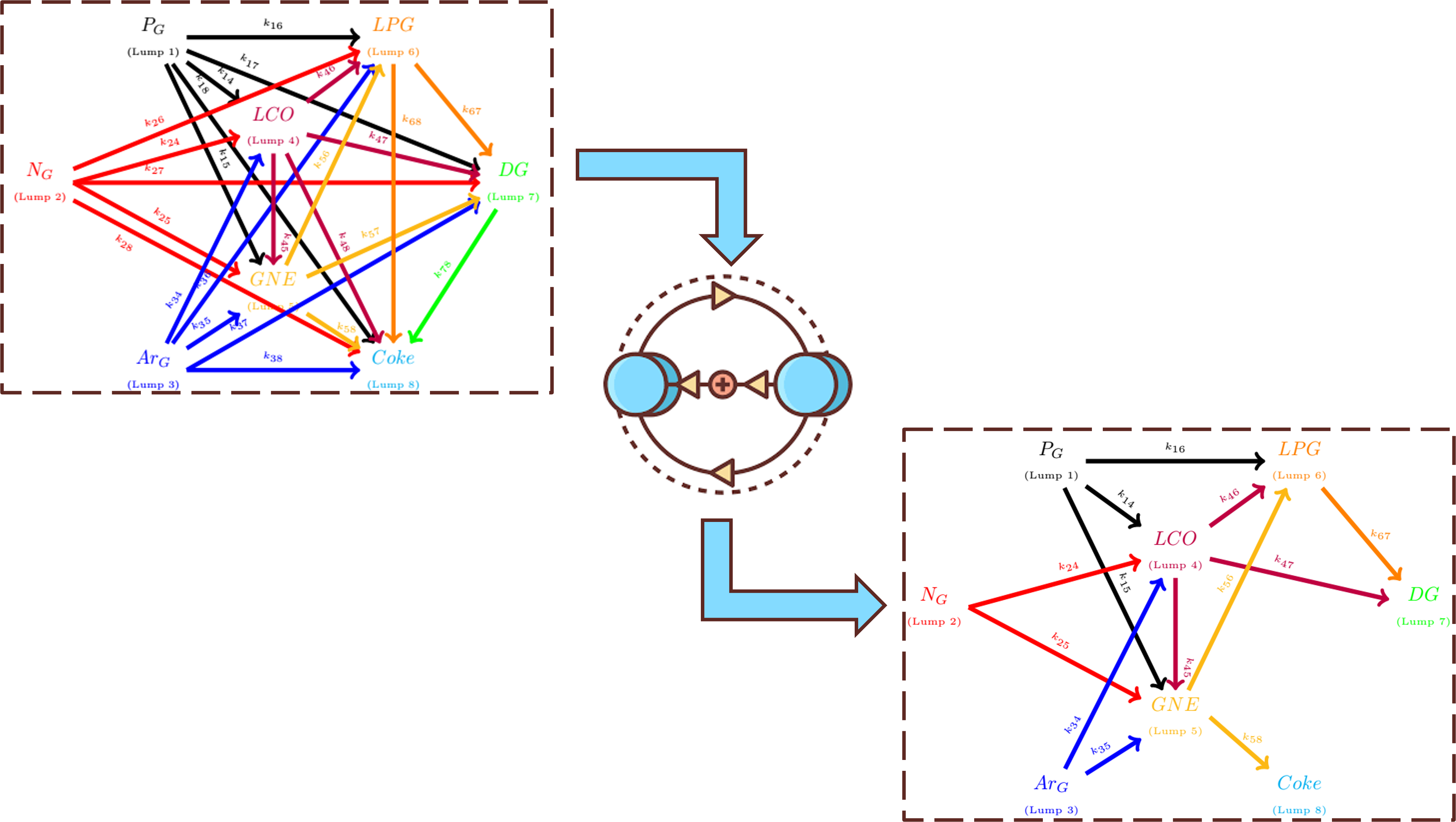
To address this issue, a fully connected reaction network was built based on an eight-lump kinetic model. The lumps represent paraffins, naphthenes, and aromatics as feedstock whereas, light cycle oil (LCO), gasoline, liquefied petroleum gas (LPG), dry gas and coke as products. The model includes 25 reactions, covering all possible transformations from heavier to lighter components.
The selection of the most relevant reaction pathways is performed using a Reinforcement Learning algorithm based on the Advantage Actor-Critic (A2C) method. In this framework, each state corresponds to a specific combination of active/inactive reactions. For every selected set of active reactions, the kinetic parameters, including activation energies, frequency factors, and deactivation parameters, are optimized.
The reward function for the RL agent is defined as the negative of the prediction error between the model and the experimental data. The model is trained using data from two different FCC feedstocks processed in an ACE-R bench-scale reactor. Experimental measurements include product distributions at four different temperatures and five time-on-stream (TOS) values, providing a robust dataset for training.
The proposed method leads to a reaction network that is consistent with known FCC behavior and discards physically unrealistic transformations.
The framework is flexible and can be retrained with additional datasets to improve or adapt the kinetic model to new feedstocks or operating conditions. Overall, this approach provides a systematic and data-driven alternative to traditional kinetic model development, reducing the need for manually defined reaction networks and offering better interpretability and performance.