2025 AIChE Annual Meeting
(394y) A Novel Method for Improving the Robustness of Data-Driven Process Models
Authors
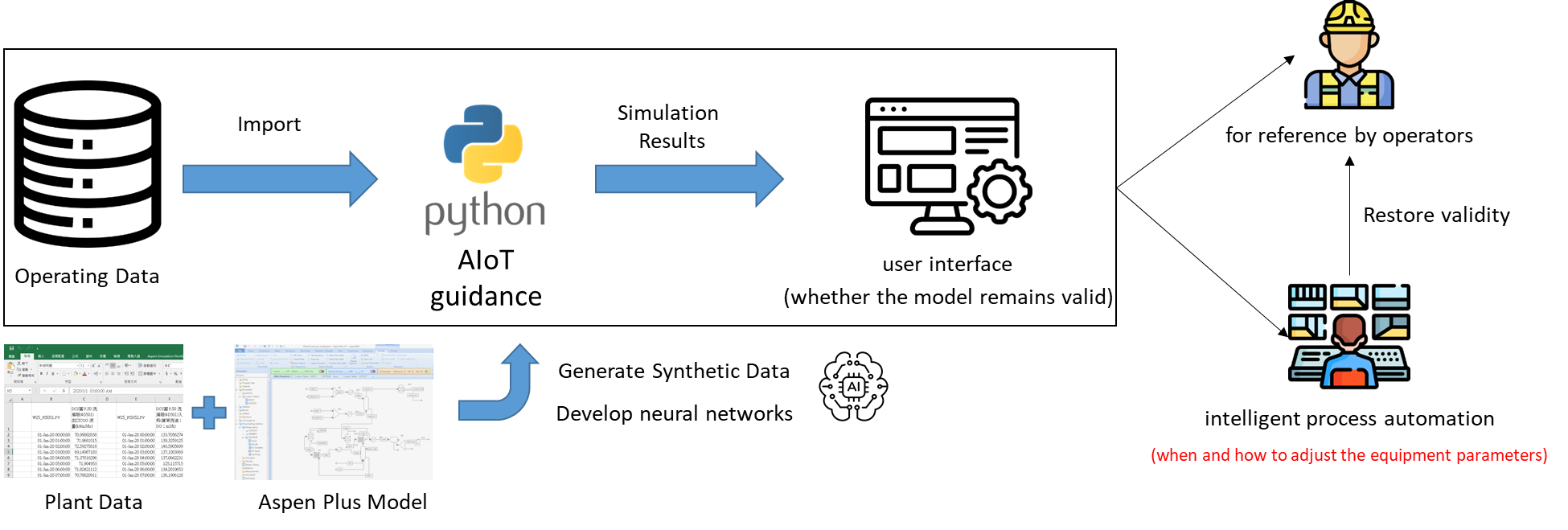
Therefore, in this work a novel method is proposed for maintaining the robustness of data-driven process models. A first-principles model of the process is constructed in a flowsheet simulator. The first-principles model is used to generate synthetic data which are combined with plant data and used to train a hybrid AI model. In addition to variables that change frequently such as production rate, variables that are indicators of the performance of the process equipment such as stage efficiency in a distillation column are also included as inputs to the model. Then if the stage efficiency of the column decreases over time due to fouling, engineers can simply update the value of the stage efficiency in the model, restoring its accuracy and predictive value.
The method is illustrated by application to a process for scrubbing benzene, toluene and xylene (BTX) from coke oven gas (COG). The process consists primarily of two units: a scrubbing column where BTX is absorbed from COG by a washing oil, and a distillation column where BTX is liberated from the washing oil and collected as a product and the regenerated oil is recycled to the scrubber. A model of the process was constructed in Aspen Plus and validated by comparison with plant data. Three years of plant data were combined with synthetic data from the Aspen Plus simulation and used to train a hybrid model. The hybrid model was tested and validated using separate data sets. The model was found to have good predictive value with the average error of each variable less than 5%. When a decrease of the stage efficiency or number of theoretical stages was simulated it was found that the predictive value of the hybrid model could be restored if these parameters were changed in the model. Retraining the model was not necessary.
Keywords
Artificial intelligence (AI), process modeling, robustness; hybrid model