2025 AIChE Annual Meeting
(392bl) Morse: Multi-Objective Reinforcement Learning Via Strategy Evolution for Supply Chain Optimization
- Introduction
Modern supply chains face growing pressure to align with sustainability principles, balancing financial performance, environmental responsibility, and social welfare — the triple bottom line principle [1, 2]. However, achieving these goals simultaneously introduces conflicting objectives that traditional inventory control methods, such as heuristics and dynamic programming, struggle to manage effectively. These approaches often optimize a single objective, leading to sub-optimal decisions in the face of complex, uncertain, and dynamically evolving environments [3].
To address this challenge, Multi-Objective Optimization (MOO) techniques have been widely used to identify Pareto-optimal solutions that balance multiple objectives. While MOO provides a static Pareto front, it struggles in dynamic environments where objective trade-offs and system conditions shift over time. Dynamic Multi-Objective Optimization (DMOO) extends MOO by computing a time-varying Pareto front as the environment changes, allowing better tracking of optimal solutions under evolving conditions. However, DMOO still lacks the ability to adapt policies in real time based on feedback from the system, making it less effective for highly volatile supply chain environments.
This gap has led to the emergence of Multi-Objective Reinforcement Learning (MORL), which combines the adaptability of reinforcement learning (RL) with the ability to balance conflicting objectives over time. RL excels in adapting policies dynamically by learning from system feedback, making it ideal for environments where conditions change frequently [6,7]. MORL extends this adaptability by dynamically learning policies that optimize multiple objectives, updating strategies as system conditions evolve. Therefore, MORL presents an opportunity to address complexities of modern supply chains whilst aligning with the triple bottom line sustainability principle - balancing profitability, social responsibility, and environmental sustainability.
- Methodology
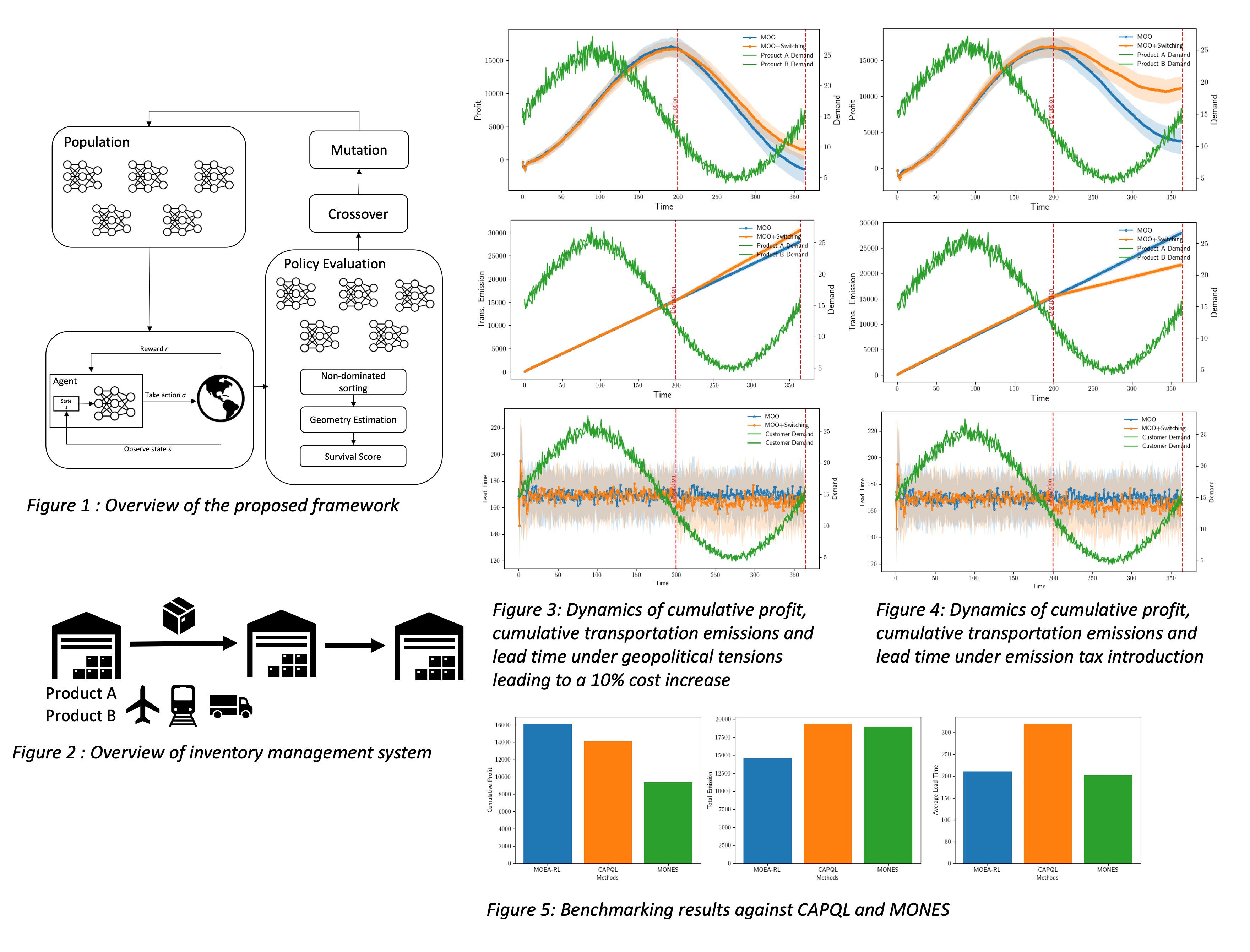
In this work, we introduce MORSE (Multi-Objective Reinforcement learning via Strategy Evolution) where we integrate multi-objective evolutionary algorithms (MOEA) within a reinforcement learning framework to find a set of adaptable policies that effectively balance three conflicting objectives (financial, environmental and, lead time). We employ the multi objective evolutionary algorithm to adapt the neural network (policy) parameters by applying the evolutionary algorithm directly to the parameter space, resulting in a Pareto front in the policy space. NSGAA-II is used to evaluate and sort the policies, resulting in a final population of policies with non-dominated solutions representing an undominated Pareto front set of policies. This strategy is inspired by recent advances demonstrating that evolutionary algorithms, when applied to policy parameter optimization, can perform on par with gradient-based reinforcement learning — as shown by OpenAI's work on Evolution Strategies (ES) [8]. We benchmark our approach against state-of-the-art MORL techniques, including gradient-based multi-policy methods showing superior performance as shown in Figure 5.
Our methodology, shown in Figure 1, employs an adaptive strategy where when a disruption hits the system (emission tax, bullwhip effect), the policy switches dynamically to another policy from the Pareto front set of policies obtained during training.
- Results and Discussion
To evaluate the effectiveness of our proposed approach, we simulate a multi-echelon, multi-product supply chain characterized by uncertain lead times and seasonal demand patterns as shown in Figure 2. The supply chain model captures interactions between multiple entities across different echelons and tracks inventory and transportation dynamics over time.
The effectiveness of our method is shown through a series of case studies simulating various disruptions as shown in Figure 3 and Figure 4. Throughout these, our approach consistently outperforms a traditional single-policy method, showcasing adaptability and robustness across diverse supply chain disruptions. Therefore, by seamlessly switching between policies from the trained Pareto set in response to disruptions, it achieves significantly improved performance and enables the integration of sustainability principles and conflicting objectives in data-driven supply chain management decision-making.
To further enhance decision-making under uncertainty, we incorporate Conditional Value-at-Risk (CVaR) to account for worst-case scenarios and mitigate high-risk outcomes. This ensures that the selected policies are not only optimal on average but also robust to extreme events, improving overall system resilience. To validate this, we compare the reward distributions of selected policies after 1,000 Monte Carlo simulations. These results highlight the superiority of our approach in managing extreme outcomes by maintaining better performance under adverse conditions, thereby reducing the likelihood of catastrophic failures in the supply chain.
Additionally, we benchmark our approach against two state-of-the-art methods — Concave-Augmented Pareto Q-Learning (CAPQL) and Multi-Objective Natural Evolution Strategies (MONES) — demonstrating superior performance in terms of overall policy quality and adaptability as shown in Figure 5.
- Conclusions
The algorithm MORSE (Multi-Objective Reinforcement learning via Strategy Evolution) is presented in this study which integrates RL with MOEAs to optimize supply chain performance across conflicting objectives. In MORSE, MOEA is used to search the policy neural network parameter space, leading to a diverse set of Pareto-optimal policies that balance financial performance, environmental sustainability, and lead time minimization. This equips the decision maker with a swarm of policies that can be dynamically switched based on the current system objectives. This strategy enhances fast decision- making, resilience, and flexibility in uncertain and changing environments. We demonstrate the effectiveness of our method through a series of case studies, which showcase its adaptability and ability to balance multiple conflicting objectives in real-time.
Future research will focus on integrating human-in-the-loop approaches that can further enhance search efficiency by leveraging expert knowledge to refine policy selection and adaptation and extending this methodology to partially observable and multi-agent environments.
[1] Guillén‐Gosálbez, G. and Grossmann, I.E., 2009. Optimal design and planning of sustainable chemical supply chains under uncertainty. AICHE journal, 55(1), pp.99-121.
[2] Mitrai, I., Palys, M.J. and Daoutidis, P., 2024. A two-stage stochastic programming approach for the design of renewable ammonia supply chain networks. Processes, 12(2), p.325.
[3] Daoutidis, P., Allman, A., Khatib, S., Moharir, M.A., Palys, M.J., Pourkargar, D.B. and Tang, W., 2019. Distributed decision making for intensified process systems. Current Opinion in Chemical Engineering, 25, pp.75-81.
[4] Avadiappan, V., 2021. Methods for Incorporating Real-Time Information in Online Scheduling. The University of Wisconsin-Madison.
[5]Mousa, M., van de Berg, D., Kotecha, N., del Rio-Chanona, E.A. and Mowbray, M., 2023. An Analysis of Multi-Agent Reinforcement Learning for Decentralized Inventory Control Systems. arXiv preprint arXiv:2307.11432.
[6] Van Moffaert, K. and Nowé, A., 2014. Multi-objective reinforcement learning using sets of pareto dominating policies. The Journal of Machine Learning Research, 15(1), pp.3483-3512.
[7] Hayes, C.F., Rădulescu, R., Bargiacchi, E., Källström, J., Macfarlane, M., Reymond, M., Verstraeten, T., Zintgraf, L.M., Dazeley, R., Heintz, F. and Howley, E., 2022. A practical guide to multi-objective reinforcement learning and planning. Autonomous Agents and Multi-Agent Systems, 36(1), p.26.
[8] Salimans, T., Ho, J., Chen, X., Sidor, S. and Sutskever, I., 2017. Evolution strategies as a scalable alternative to reinforcement learning. arXiv preprint arXiv:1703.03864.