2025 AIChE Annual Meeting
(679a) Large Language Model Agents for User-Friendly Chemical Process Simulations
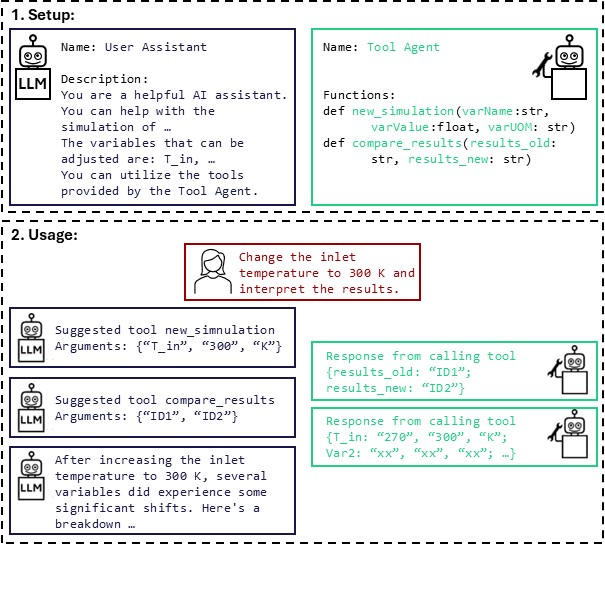
Our approach is built upon a Python-based interface encapsuling the core simulation functionalities as discrete tools. Using the Autogen package [2], the LLM agent is programmed to understand user-provided tasks and decide which tool to employ based on the natural language description. For instance, the agent interprets the simulation requirements, calls the appropriate Python function linked to the AVEVA Process Simulation software, and retrieves key process variables for analysis. Further, a visualization agent could be employed to process the data and generate informative plots, enhancing the user's comprehension of the simulation outcomes.
This proof-of-concept was validated through different case studies, one targeting a water-methanol distillation column. For instance, the LLM agent was ordered to change the inlet stream temperature. The system correctly interpreted the instruction, sequentially invoked the proper Python functions to simulate and obtain data, and ultimately provided a clear summary of the resulting changes, including an interpretation. In another example, we mandate optimizing the distillation column by adjusting the boil-up and reflux ratios. The objective was to minimize the heating demand in the reboiler while achieving a molar composition of at least 0.99 of water in the bottom and at least 0.95 of methanol in the distillate. The framework autonomously ran multiple simulations, identified optimal parameter combinations, and explained the simulation outcomes. In our case studies, we evaluated cloud-based and locally deployed LLM models, ensuring that sensitive data can be processed securely on local systems while utilizing cloud APIs for non-sensitive tasks.
In addition to demonstrating technical feasibility, our work addresses the responsible use of LLM agents in process simulation. We discuss strategies for evaluating the trustworthiness and accuracy of LLM-generated interpretations, emphasizing the need for expert validation when assessing simulation outcomes for critical decisions. To further enhance the reliability of the interpretation process, we propose integrating a knowledge database and leveraging retrieval augmented generation (RAG) techniques [3]. These enhancements aim to refine the LLM’s performance and ensure that its outputs support safe and effective decision-making. Overall, our framework shows promising potential to boost productivity, facilitate educational engagement, and supply high-quality datasets for advanced model training in chemical engineering, including applications in digital twins development, fault diagnosis, and LLM fine-tuning.
References:
[1] Ghasem, Nayef. Computer methods in chemical engineering. CRC Press, 2021.
[2] Wu, Qingyun, et al. "Autogen: Enabling next-gen llm applications via multi-agent conversation." arXiv preprint arXiv:2308.08155 (2023).
[3] Li, Jiarui, Ye Yuan, and Zehua Zhang. "Enhancing llm factual accuracy with rag to counter hallucinations: A case study on domain-specific queries in private knowledge-bases." arXiv preprint arXiv:2403.10446 (2024).