2025 AIChE Annual Meeting
(391m) Clustering-Based Filtering for Variable Definition Equivalence Judgment Task
Physical models are fundamental to simulation, optimization, and control tasks across many domains; however, constructing accurate models remains labor-intensive and reliant on expert knowledge. This circumstance has motivated the development of automated modeling techniques, such as symbolic regression [1] and information extraction from literature using natural language processing (NLP) methods [2]. Building on this direction, we have aimed to realize Automated Physical Model Builder (AutoPMoB) [3], a system that automates literature retrieval, information extraction, and model generation from literature sources. A key challenge in this pipeline is the semantic unification of variable definitions since the same physical concept may be described differently across documents (e.g., "feed stream" vs. "feed flow rate to the reactor"). Judging whether two variable definitions are semantically equivalent, termed the variable definition equivalence judgment (VDEJ) task, is difficult due to linguistic variability and limited annotated data, especially equivalent samples.
This study addresses the class imbalance in the VDEJ task. We propose a clustering-based filtering method that leverages dense vector embeddings of variable definitions to eliminate trivial non-equivalent pairs. This enables classifiers in the following task to focus on semantically similar and ambiguous cases. We also evaluate the effects of input design and embedding model choice on clustering effectiveness.
Methods
Our approach combines dense vector classification with clustering-based filtering. The method comprises (1) definition vectorization, (2) dimensionality reduction and clustering, and (3) non-equivalent sample filtering. Unsupervised clustering identifies trivially dissimilar pairs, allowing the classifier to target more challenging examples.
Embedding Generation
Each definition is encoded into a dense vector using the all-MiniLM-L6-v2 [4] or SciBERT [5] models. The former is a general-purpose lightweight model trained on a diverse corpus, and the latter is a BERT-based model pre-trained on scientific texts. To investigate the effect of contextual information, we consider four input formats:
- D: Definition only (e.g., "feed stream"),
- D+S: Definition with Symbol (e.g., "feed stream (F^e)"),
- D+C: Definition with its sentence context (e.g., "feed stream. The ... heat, respectively."), and
- D+S+C: Combination of definition, symbol, and context (e.g., "feed stream (F^e). The ... heat, respectively.").
Each input text is tokenized and passed through a language model, and the final sentence embedding is obtained by applying mean pooling over the token embeddings.
Dimensionality Reduction and Clustering
To identify semantically similar definitions, we apply UMAP [6] for projection and HDBSCAN [7] for clustering. This strategy mimics that used for BERTopic [8]. UMAP projects high-dimensional embeddings into a two-dimensional space with a characteristic of more effective clustering while preserving local structure. HDBSCAN identifies clusters based on density, where definitions assigned to different clusters are considered trivially dissimilar. Definitions assigned to different clusters are considered non-equivalent; unclustered points (classified as noise) are handled separately. Hyperparameters are selected via grid search using one-paper-out cross-validation.
Filtering and Classification
Pairs across clusters are labeled non-equivalent, while those within clusters are marked "unknown" and retained for further classification. Noisy pairs, which include one unclustered point, are handled using two strategies: labeling them as non-equivalent or postponing judgment by assigning them "unknown."
Experiments
Dataset Preparation
We prepared a dataset from five papers on a continuous stirred tank reactor (CSTR). For each paper, variable symbols and their corresponding definitions were annotated with the full sentence in which each definition appeared [9]. We created all possible pairs from the annotated definitions and manually labeled each as equivalent or non-equivalent based on the semantic equivalence of the definitions, regardless of differences in symbols. For instance, the definitions "feed stream" and "feed flow rate to the reactor" were labeled as equivalent despite having different symbols (e.g., "F^e" and "F"). 1,696 definition pairs were made, with 42 labeled as equivalent.
All five papers were used as test data one by one: for each test paper, the remaining four served as training and validation data in a one-paper-out cross-validation scheme. This condition ensures that the model is evaluated on unseen definitions from a different source, which simulates a realistic scenario. The hyperparameters were tuned based on validation performance, and the final clustering model was evaluated on the test pairs.
Results and Discussion
Our method achieved high precision and recall in identifying non-equivalent pairs. When noisy pairs were treated as "unknown," precision and recall reached 0.969 and 0.647, respectively, offering a better balance than treating them as non-equivalent (0.982 and 0.531). For example, with the paper by Poyton et al. [10] as test data, recall improved from 0.228 to 0.745 by judging noisy pairs as "unknown," while the exclusion rate of test pairs dropped from 78% to 25%. In addition, the findings that the D+C input format outperformed D+S demonstrated the benefit of contextual embeddings.
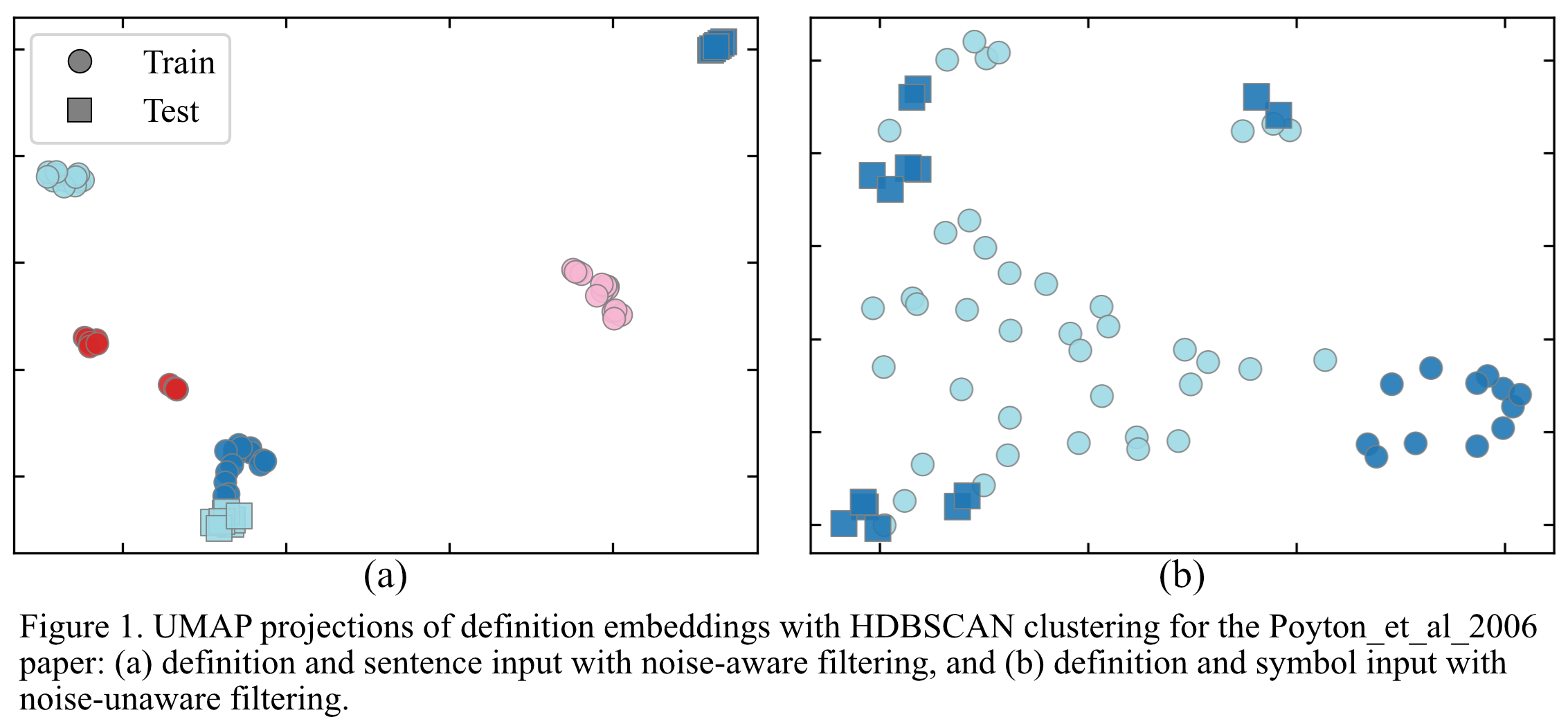
Figure 1 shows two examples of clustering results when the test paper is the one by Poyton et al. In Figure 1(a), where noisy pairs are treated as "unknown" and D+C is used as input, clusters are compact and test points (square plots) are distributed across them. In contrast, Figure 1(b), where noisy pairs are judged as non-equivalent and the D+S is input, shows less coherent clusters and a higher number of isolated or ambiguously placed test points. This UMAP visualization confirms that contextual input and careful noise handling can produce tighter, more meaningful clusters and increase the likelihood that potentially equivalent definitions will hold. This approach improves quantitative performance and can mitigate annotation and computation costs by filtering only informative candidate pairs.
Conclusion
We proposed a clustering-based approach to filter non-equivalent samples in the VDEJ task. The method reduces the burden on classifiers by identifying and removing trivially dissimilar pairs using UMAP and HDBSCAN. Experimental results demonstrated that this approach improved both the precision-recall balance and the overall robustness of equivalence filtering. In addition, noise-aware filtering and context-rich embeddings enhanced recall without sacrificing precision. This strategy could support scalable annotation and model development for scientific text understanding.
Future work will expand the dataset and integrate this filtering method with classifier architectures, including transformer-based and large language models, toward automated and accurate model construction from the scientific literature.
Acknowledgment
This work was supported by JST, ACT-X Grant Number JPMJAX23C5, Japan.
References
[1] M. Á. de Carvalho Servia et al., The automated discovery of kinetic rate models – methodological frameworks, Digital Discovery, 2024, 3, 954–968.
[2] M. S.-Wilhelmi et al., 2025. LLM-based data extraction in chemistry, Chemical Society Reviews, 54, 1125–1150.
[3] S. Kato and M. Kano, 2024. Prototype of Automated Physical Model Builder: Challenges and Opportunities, Computer Aided Chemical Engineering, 53, 2839–2844.
[4] N. Reimers and I. Gurevych, 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks, EMNLP-IJCNLP, 3982–3992.
[5] I. Beltagy, K. Lo, and A. Cohan, 2019. SciBERT: A Pretrained Language Model for Scientific Text, EMNLP-IJCNLP, 3615–3620.
[6] L. McInnes, J. Healy, and J. Melville, 2018. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, arXiv preprint arXiv:1802.03426.
[7] R.J.G.B. Campello et al., 2015. Hierarchical density estimates for data clustering, visualization, and outlier detection, ACM transactions on knowledge discovery from data, 10, 1, 1–51.
[8] M. Grootendorst, 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure, arXiv preprint arXiv:2203.05794.
[9] S. Kato and M. Kano, 2025. VARAT: Variable Annotation Tool for Documents on Manufacturing Processes, Journal of Chemical Engineering of Japan, 58, 1.
[10] A. A. Poyton et al., 2006. Parameter estimation in continuous-time dynamic models using principal differential analysis, Computers & Chemical Engineering, 30, 4, 698–708.