2025 AIChE Annual Meeting
(390ai) Automating Distillation Column Internals Design Via Soft-Actor Critic Reinforcement Learning: A Hybrid Action Space Approach
Authors
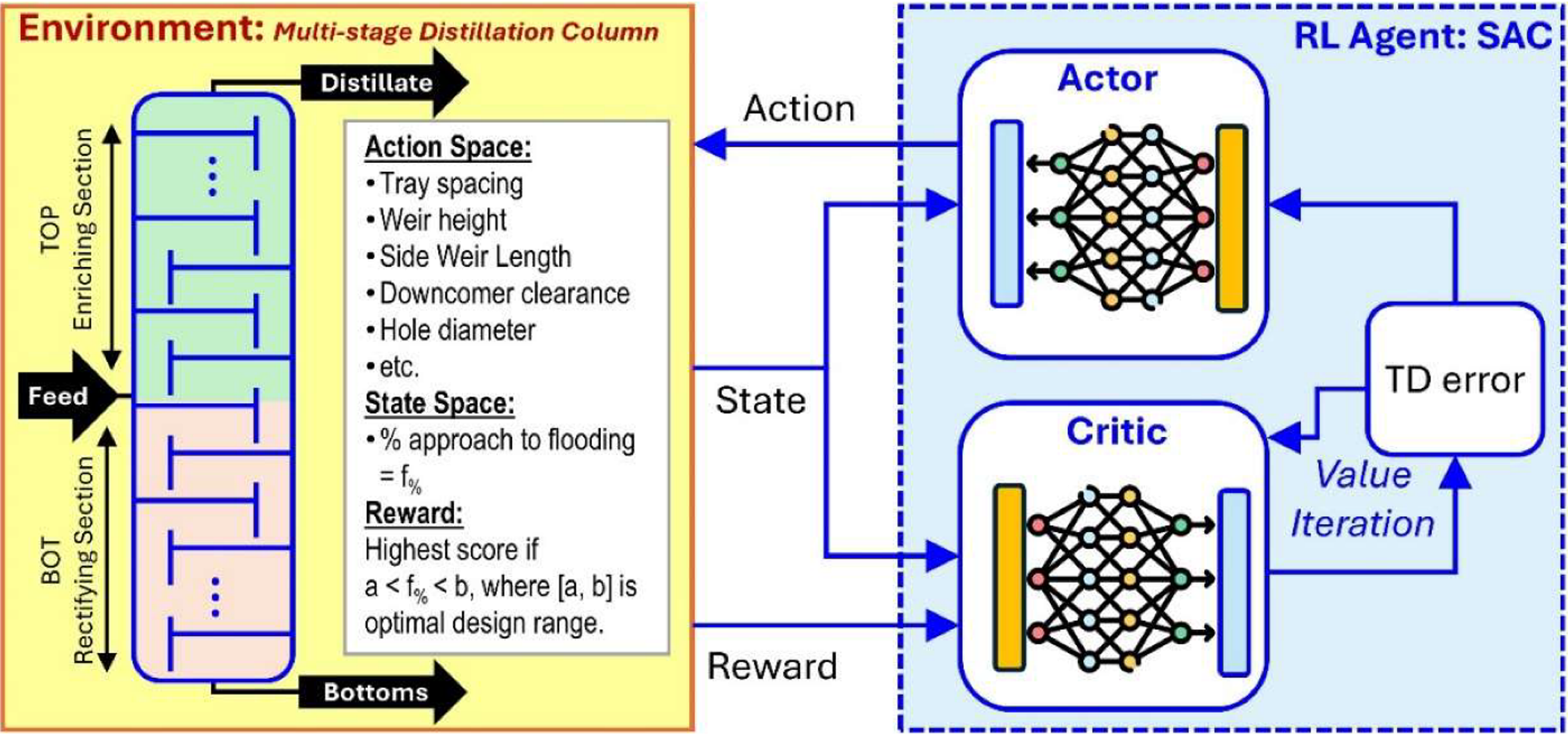
Distillation column internals design remains a challenging bottleneck in chemical process design. Commercial process simulators like Aspen Plus® excel at rigorous modeling but still rely on engineers to manually iterate on internal design parameters (tray spacing, diameters, packing types, etc.), often requiring extensive time and potentially yielding sub-optimal designs. This manual trial-and-error is especially inefficient for high-dimensional design spaces with many interacting parameters. Reinforcement learning (RL) offers a promising avenue to automate and accelerate this design optimization task. In particular, the Soft Actor-Critic (SAC) algorithm – an off-policy RL method for continuous action spaces – has shown success in process control and optimization problems. [1]
In the first phase of our research, we applied SAC to optimize trayed distillation column internals. The SAC agent interacted with an Aspen Plus RadFrac simulation model of a multistage distillation column, adjusting tray geometry variables and receiving feedback on process performance. A custom Python interface was used, and an OpenAI Gymnasium environment linked the RL algorithm with Aspen Plus, enabling automated simulation runs in the loop [1]. The agent rapidly learned an optimal policy for tray internals design, confirming RL as a viable automation tool. This can be seen in the figure below which graphs Reward vs Episode. This early work also provided insight into effective hyperparameter settings (learning rates, exploration noise, reward shaping), which informed the configuration used in our hybrid action space framework. [1]
Expanding the Action Space in RL-Based Distillation Design
While our earlier work demonstrated that RL could automate trayed column design, it remained constrained to a single internal type and a continuous action space. Industrial column design, however, often begins with a categorical decision between trays and various forms of packing, a choice that dramatically alters the relevant design variables. In this current phase, we extend our framework to tackle this more realistic hybrid action space, where the agent must learn both what internal type to select (discrete) and how to configure it (continuous/discrete).
This extension elevates the automation task from parameter tuning to strategic decision-making, reflecting how engineers approach real-world distillation design.
Formalizing Hybrid Actions in Distillation Design
The hybrid action space consists of two levels:
- Discrete Action Layer: The system selects between trayed and packed column configurations. If packed internals are selected, it further chooses the specific packing type (a type of random/structured packing).
- Conditional Continuous Layer: Once the internal type is selected, a set of geometry or configuration parameters is proposed, such as tray spacing, weir height.
This hierarchical formulation reflects real-world engineering decisions and enables exploration across fundamentally different design techniques, but it also introduces algorithmic challenges beyond that of standard SAC or DQN implementation. [2]
Hybrid SAC-PDQN: Coordinated Agents for Mixed Action Spaces
To support learning in this mixed decision space, we implemented a two-agent architecture that combines the strengths of complementary reinforcement learning types:
- A discrete agent based on PDQN principles selects the internal type and packing configuration, using Q-learning techniques to handle categorical decisions efficiently.
- A continuous agent built on Soft Actor-Critic (SAC) learns to tune geometry parameters specific to the selected internal type, providing stable, entropy-regularized updates over continuous spaces.
Rather than combining both roles into a single policy, our modular design separates them into independently optimized agents. The discrete agent acts first, and its output determines the continuous agent's activation, a design that simplifies training while preserving a clean action hierarchy.
This split-agent design allows us to use the best of both frameworks while enabling greater control over reward shaping and exploration dynamics within each space. Together, these agents form a hybrid decision layer that adapts not just parameter values, but entire column internals. [3]
System Integration: Automating Aspen Plus in the Loop
To allow the RL agents to interact directly with Aspen Plus, we extended the Python–Aspen interface developed in prior work. Each episode proceeds through the following loop:
- The discrete agent selects an internal configuration.
- The continuous/discrete agent produces parameter values for the chosen internal.
- Aspen Plus is reconfigured accordingly:
- Tray/Packed internals are selected,
- Geometry parameters are injected into the input file.
To support this flow, we created a robust interface that translates hybrid action vectors into Aspen COM API commands. This allows the agent to explore a rich design space autonomously, running hundreds of simulations without manual intervention.
Challenges and Engineering Solutions
- Agent Coordination: The two-agent system required synchronization logic to ensure that the discrete selection of internals correctly gated the activation of the design parameters. This was handled by a shared context layer that bridges state information between the agents and ensures valid conditional action sequences.
- Training Pipeline: Since SAC and PDQN follow different learning paradigms (stochastic policy gradients vs. Q-learning), so we extended the replay buffer to accommodate hybrid actions and compute compatible update targets. We ensured that the entropy regularization applied to both action layers remained effective for exploration, even when optimizing a single metric (flooding).
- Reward Normalization: With flooding percentage as the central design target, we tailored the reward function to consistently penalize over-flooding and reward proximity to a target flooding window (e.g., 80–90% for trayed and 65-75% for packed). This avoided ambiguity in reward attribution and ensured stable learning even during early episodes where agent actions produced invalid or extreme flooding values.
Results: Learned Internals and Flooding-Optimized Designs
The hybrid reinforcement learning system, composed of a discrete agent for selecting internals/tuning parameters and a continuous agent for tuning design parameters, successfully converged on column configurations that minimized flooding percentage while maintaining operational feasibility. Although flooding was the sole optimization objective, the system demonstrated structured decision-making behavior that reflects real engineering choices.
Key performance highlights:
- Focused Adaptability: Despite being guided exclusively by flooding percentage, the agent learned to navigate a hybrid action space and adapt its strategy across different internal types and column setups.
- Stable Convergence: Learning curves were smooth, with cumulative reward improving steadily over training episodes. The agent reliably designed flooding % into the optimal range over time, confirming its ability to extract and apply useful patterns from the environment.
- Physical Validity: All final configurations proposed by the agent were validated in Aspen Plus and met the expected physical constraints — including feasible internal configurations and non-flooding operation — with no need for manual correction.
This outcome highlights the capability of the hybrid reinforcement learning framework to automate complex design decisions using a single, focused optimization target — flooding percentage. The agent’s ability to choose between different internal types and adjust their configurations solely to minimize flooding demonstrates that it is learning physically meaningful, engineering-relevant behaviors. Even with flooding as the only reward signal, the system exhibits strategic and interpretable control. This focused success establishes a solid foundation for future extensions, where additional process objectives can be incorporated without reworking the core architecture.
Broader Impacts and Significance
This project demonstrates the potential of reinforcement learning (RL) to automate complex chemical process design tasks that have traditionally required extensive manual iteration, with a focus on distillation column internals. By coupling Aspen Plus simulations with a coordinated dual-agent hybrid RL framework, the system significantly reduces the time engineers spend iterating designs. This frees them to focus on higher-level strategic decisions. The ability of this multi-agent system to autonomously navigate hybrid action spaces and make informed, design-relevant decisions underscores RL's practical utility and scalability. Beyond industry applications, these tools can enhance chemical engineering education by enabling students to explore design trade-offs in an interactive and data-driven way. As a generalizable architecture, this hybrid RL approach sets the stage for automating a broad range of engineering tasks that involve intertwined discrete and continuous decisions — marking a shift toward faster, smarter, and more autonomous design workflows in process systems engineering.
References:
- D. L. B. Fortela et al., “Soft Actor-Critic Reinforcement Learning Improves Distillation Column Internals Design Optimization,” Preprints.org 2025 .
- J. Xiong et al., “Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space,” arXiv:1810.06394, 2018
- O. Delalleau et al., “Discrete and Continuous Action Representation for Practical RL in Video Games (Hybrid SAC),” AAAI Workshop on RL in Games, 2020