2024 AIChE Annual Meeting
(735bn) Template-Based Sentence Generation for Variable Definition Extraction from Papers on Chemical Processes
Physical models are crucial in designing processes and optimizing operational conditions in the process industry. Process simulators based on physical models exist for some processes, but they do not apply to all processes. When dealing with a process for which no suitable simulator is available, it is necessary to construct a new physical model. However, constructing physical models that can accurately replicate the behavior of the target process requires a thorough review of existing literature to gather and assimilate a substantial amount of information. To facilitate this labor-intensive task, we aim to realize Automated Physical Model Builder (AutoPMoB), which automatically builds desired physical models from relevant documents [1]. A key component of this system is a method for accurately extracting variable definitions from documents.
In the task of variable definition extraction, methods employing pre-trained models, such as BERT (Bidirectional Encoder Representations from Transformers) [2], have shown promising results. Yamamoto et al. [3] achieved the highest performance in extracting variable definitions from chemical process-related papers using a BERT model. Their method takes a sentence with a target variable and replaces the target variable with a special token. The sentence is then inputted to the BERT model and the position of the corresponding variable definition is obtained. They constructed a definition extraction model through a two-step fine-tuning process, first using the Symlink dataset [4] comprising five fields with low relevance to chemical processes, followed by a dataset related to chemical processes, achieving an accuracy of 85.5%. However, since variable definition extraction is an upstream process in AutoPMoB and influences the overall performance, its performance should be nearly perfect. From this perspective, the method developed by Yamamoto et al., despite its achievements, falls short of the necessary standards for AutoPMoB.
To enhance the variable definition extraction performance, we focus on the size of the training data used by Yamamoto et al. The size is smaller than that used in related studies; thus, the performance can be improved by increasing the training data. However, since the characteristics of variable definitions, such as their lengths and the words they contain, differ across fields, the difficulty of variable definition extraction also varies by field [5]. Therefore, increasing training data in other fields may not improve the performance. Besides, generating substantial new data for each field requires a high cost. To overcome these obstacles, we propose a method of expanding the training data in this study.
Proposed Method
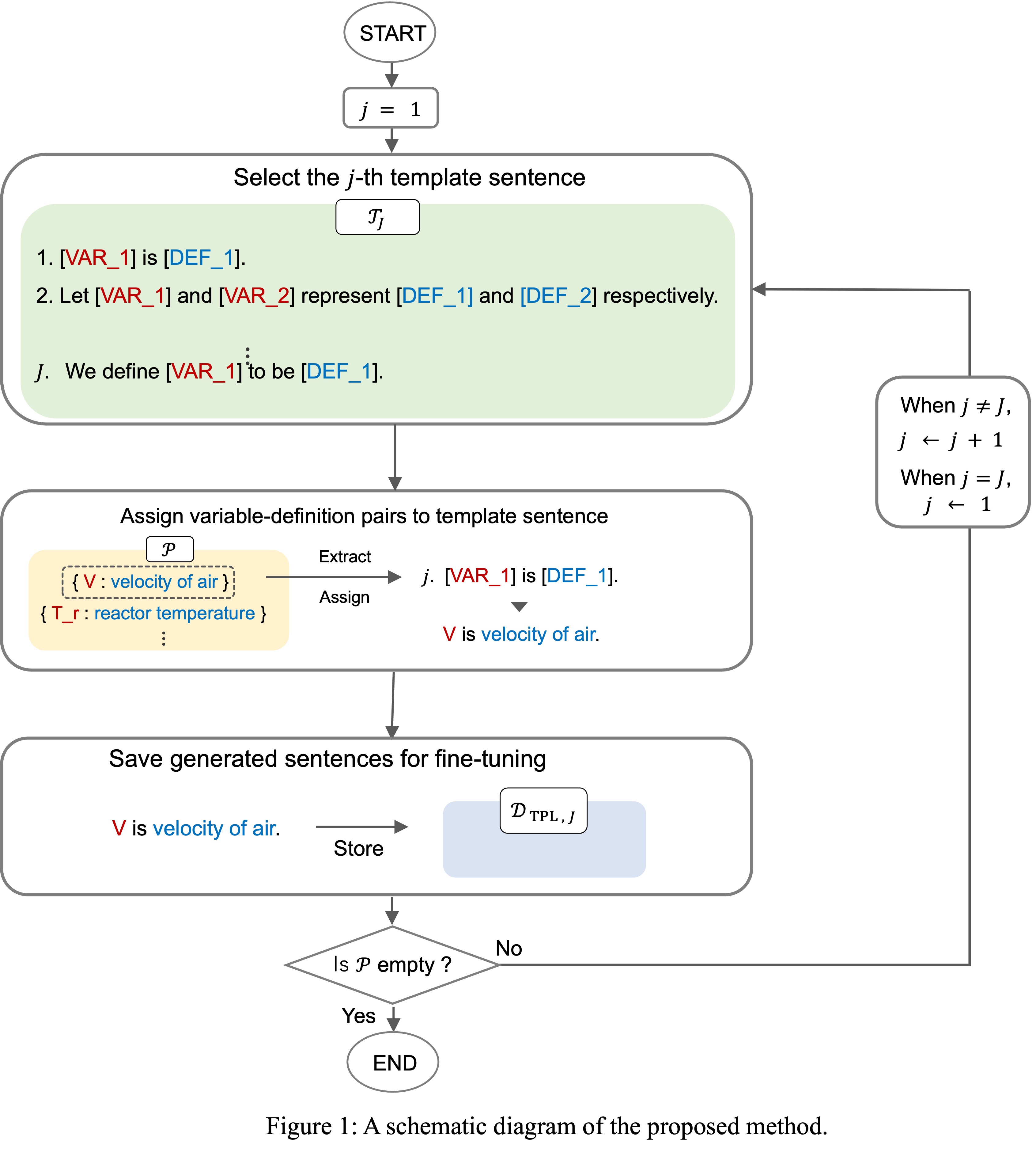
The diagram in Figure 1 outlines our proposed approach. Initially, we prepare a set of template sentences using ChatGPT, such as “[VAR] is defined as [DEF].” The prompts for ChatGPT include detailed instructions on the desired output format, the number of variables in the sentence to be generated, and examples. The proposed method generates new definition sentences by substituting variables and definitions from existing training data into these template sentences. The generation of definition sentences continues until all variables in the training data are used.
Results and Discussion
We evaluated our model, trained with the training data augmented by the proposed method, against the model developed by Yamamoto et al., using a dataset created from 47 papers on five chemical processes. Our model achieved an accuracy of 89.6%, which surpassed Yamamoto et al.’s model by 2.8 percentage points. Notably, our model maintained high accuracy even without using data from the test for training, a scenario where the existing method’s performance typically declines. Although overall definition extraction performance was improved, there remain cases where both existing and proposed methods fail, such as sentences with multiple variables, definitions, and equations. The template sentences created in this study were more straightforward than the actual definition sentences; for example, they contained multiple [VAR]s and [DEF]s, but all of them were mapped to each other, and no equation was included in the templates. Further performance improvements can be expected by developing a method of creating template sentences that more closely resemble the definition sentences appearing in the dataset.
Acknowledgment
This work was supported by JSPS KAKENHI Grant Number JP23K13595.
References
[1] Kato, S. and Kano, M.: Towards an Automated Physical Model Builder: CSTR Case Study, Computer Aided Chemical Engineering, vol. 49, pp. 1669–1674 (2022)
[2] Devin, J., Chang, M.W., Lee, K., and Toutanova, K.: BERT: Pretraining of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4171–4186 (2019)
[3] Yamamoto, M., Kato, S., and Kano, M.: Variable definition extraction by BERT with two-step fine-tuning. In: Proceedings of the 29th Annual Conference of the Association for Natural Language Processing. pp. 2957–2961 (2023)
[4] Lai, V.D., Veyseh, A.P.B., Dernoncourt, F., and Nguyen, T.H.: Semeval 2022 task 12: Symlink - linking mathematical symbols to their descriptions. In: Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022). pp. 1671–1678 (2022)
[5] Popovic, N., Laurito, W., and Färber, M.: AIFB-WebScience at SemEval-2022 task 12: Relation extraction first - using relation extraction to identify entities. In: Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022). pp. 1687–1694 (2022)